Nikolaos Dimitriadis
Nikolaos Dimitriadis
Home
Publications
Contact
CV
1
MEMOIR: Lifelong Model Editing with Minimal Overwrite and Informed Retention for LLMs
Language models deployed in real-world systems often require post-hoc updates to incorporate new or corrected knowledge. However, …
Ke Wang
,
Yiming Qin
,
Nikolaos Dimitriadis
,
Alessandro Favero
,
Pascal Frossard
Cite
URL
LiNeS: Post-training layer scaling prevents forgetting and enhances model merging
Fine-tuning pre-trained models has become the standard approach to endow them with specialized knowledge, but it poses fundamental …
Ke Wang
,
Nikolaos Dimitriadis
,
Alessandro Favero
,
Guillermo Ortiz-Jimenez
,
Francois Fleuret
,
Pascal Frossard
Cite
PDF
GitHub Repository
Website
Pareto Low-Rank Adapters: Efficient Multi-Task Learning with Preferences
Multi-task trade-offs in machine learning can be addressed via Pareto Front Learning (PFL) methods that parameterize the Pareto Front …
Nikolaos Dimitriadis
,
Pascal Frossard
,
Francois Fleuret
Cite
PDF
Localizing Task Information for Improved Model Merging and Compression
Ke Wang
,
Nikolaos Dimitriadis
,
Guillermo Ortiz-Jimenez
,
Francois Fleuret
,
Pascal Frossard
Cite
PDF
Website
GitHub repository
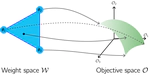
Pareto Manifold Learning: Tackling Multiple Tasks via Ensembles of Single-Task Models
We present a novel approach to multi-task learning, that utilizes weight ensembles to produce a continuous Pareto Front in a single training run.
Nikolaos Dimitriadis
,
Pascal Frossard
,
Francois Fleuret
PDF
Cite
Poster
Slides
GitHub repository
SequeL: A Continual Learning Library in PyTorch and JAX
Nikolaos Dimitriadis
,
Francois Fleuret
,
Pascal Frossard
PDF
Cite
Website
GitHub repository
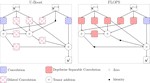
U-Boost NAS: Utilization-boosted Differentiable Neural Architecture Search
Optimizing resource utilization in target platforms is key to achieving high performance during DNN inference. While optimizations have …
Ahmet Caner Yüzügüler
,
Nikolaos Dimitriadis
,
Pascal Frossard
PDF
Cite
Poster
Slides
Video
GitHub repository
Advances in Morphological Neural Networks: Training, Pruning and Enforcing Shape Constraints
In this paper, we study an emerging class of neural networks, the Morphological Neural networks, from some modern perspectives. Our …
Nikolaos Dimitriadis
,
Petros Maragos
PDF
Cite
Poster
Slides
Video
Cite
×